LM Studio 서버로 나만의 LLM 채팅 서비스 제작하는 방법

LM Studio 서버로 나만의 LLM 채팅 서비스 제작하는 방법
이전 포스팅에서 LM Studio 를 이용해 LLM Local Server 를 실행해 봤습니다
2024.06.06 - [코딩/Python_AI] - LM Studio 에서 LLM 로컬 서버 띄우기
LM Studio 에서 LLM 로컬 서버 띄우기
LM Studio 에서 LLM 로컬 서버 띄우기 허깅페이스에 가면 정말 많은 LLM 모델들이 있습니다.이 모델들을 활용하여 로컬 서버에 나만의 gpt 서버를 구축하고 싶다면LM Studio 를 이용하여 아주 쉽게 LLM
keistory.tistory.com
LM Studio 로 띄운 로컬서버에 질의 하는 방법을 알아봅니다.
이전 시간에 OpenAI 로 질의하는 방법을 알아봤는데요
2024.06.08 - [코딩] - streamlit 으로 나만의 GPT 채팅 서비스 제작하는 방법
streamlit 으로 나만의 GPT 채팅 서비스 제작하는 방법
streamlit 으로 나만의 GPT 채팅 서비스 제작하는 방법 먼저 OpenAPI 에서 Key 를 발급받아야 합니다.2024.06.08 - [코딩/Python_AI] - Open API 사용을 위한 Key 발급 받기 및 요금 Open API 사용을 위한 Key 발급 받
keistory.tistory.com
위 코드를 변경해 봤습니다.
schat_lmstudio.py
import streamlit as st
from utils import print_messages, StreamHandler
from langchain_core.messages import ChatMessage
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 메시지 기록
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
st.set_page_config(page_title="S Chat", page_icon="💬")
st.title("💬Streamlit LM CHAT")
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 채팅 대화 기록을 저장하는 store 세션 상태 변우
if "store" not in st.session_state:
st.session_state["store"] = dict()
with st.sidebar:
session_Id = st.text_input("Session ID", "test_session")
clear_button = st.button("대화기록 초기화")
if clear_button:
st.session_state["messages"] = [] #화면 상 대화 내용 삭제
st.session_state["store"] = dict() #대화 저장 기록 제거
st.experimental_rerun()
# 무조건 리프레시가 일어나 이전 대화내용 저장하고 출력해야 대화 내용이 유지됨
print_messages()
store = st.session_state["store"] # 세션 기록을 저장할 딕셔너리
# 세션 ID를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids: str) -> BaseChatMessageHistory:
print(session_ids)
if session_ids not in store: # 세션 ID가 store에 없는 경우
# 새로운 ChatMessageHistory 객체를 생성하여 store에 저장
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 해당 세션 ID에 대한 세션 기록 반환
if user_input := st.chat_input("메시지를 입력해 주세요."):
# 사용자가 입력한 내용
st.chat_message("user").write(f"{user_input}")
st.session_state["messages"].append(ChatMessage(role="user", content=user_input))
# AI 가 답변한 내용
with st.chat_message("assistant"):
#msg = f"당신이 입력한 내용 : {user_input}"
stream_handler = StreamHandler(st.empty())
# 1. 모델 생성 - LM Studio Server
llm = ChatOpenAI(streaming=True, callbacks=[stream_handler],
base_url="http://kjun.local:3070/v1",
api_key="lm-studio",
model="teddylee777/EEVE-Korean-Instruct-10.8B-v1.0-gguf")
# 2. 프롬프트 생성
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"질문에 대하여 간결하게 답변해 주세요",
),
# 대화 기록을 변수로 사용, history 가 MessageHistory 의 key 가 됨
MessagesPlaceholder(variable_name="history"),
("human", "{question}"), # 사용자 입력을 변수로 사용
]
)
chain = prompt | llm # 프롬프트와 모델을 연결하여 chain 객체 생성
chain_with_memory = (
RunnableWithMessageHistory( # RunnableWithMessageHistory 객체 생성
chain, # 실행할 chain 객체
get_session_history, # 세션 기록을 가져오는 함수
input_messages_key="question", # 사용자 질문의 키
history_messages_key="history", # 기록 메시지의 키
)
)
# 기록 기반
response = chain_with_memory.invoke(
{"question": user_input},
config={"configurable": {"session_id": session_Id}})
msg = response.content
st.session_state["messages"].append(ChatMessage(role="assistant", content=msg))
utils.py
import streamlit as st
def print_messages() :
# 이전 대화기록 출력
if "messages" in st.session_state and len(st.session_state["messages"]) > 0 :
for chat_message in st.session_state["messages"]:
#st.chat_message(role).write(message)
st.chat_message(chat_message.role).write(chat_message.content)
from langchain.callbacks.base import BaseCallbackHandler
# 답변을 실시간으로 표시해 주기
class StreamHandler(BaseCallbackHandler):
def __init__(self, container, initial_text=""):
self.container = container
self.text = initial_text
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.text += token
self.container.markdown(self.text)
실행
streamlit run schat_lmstudio.py
결과
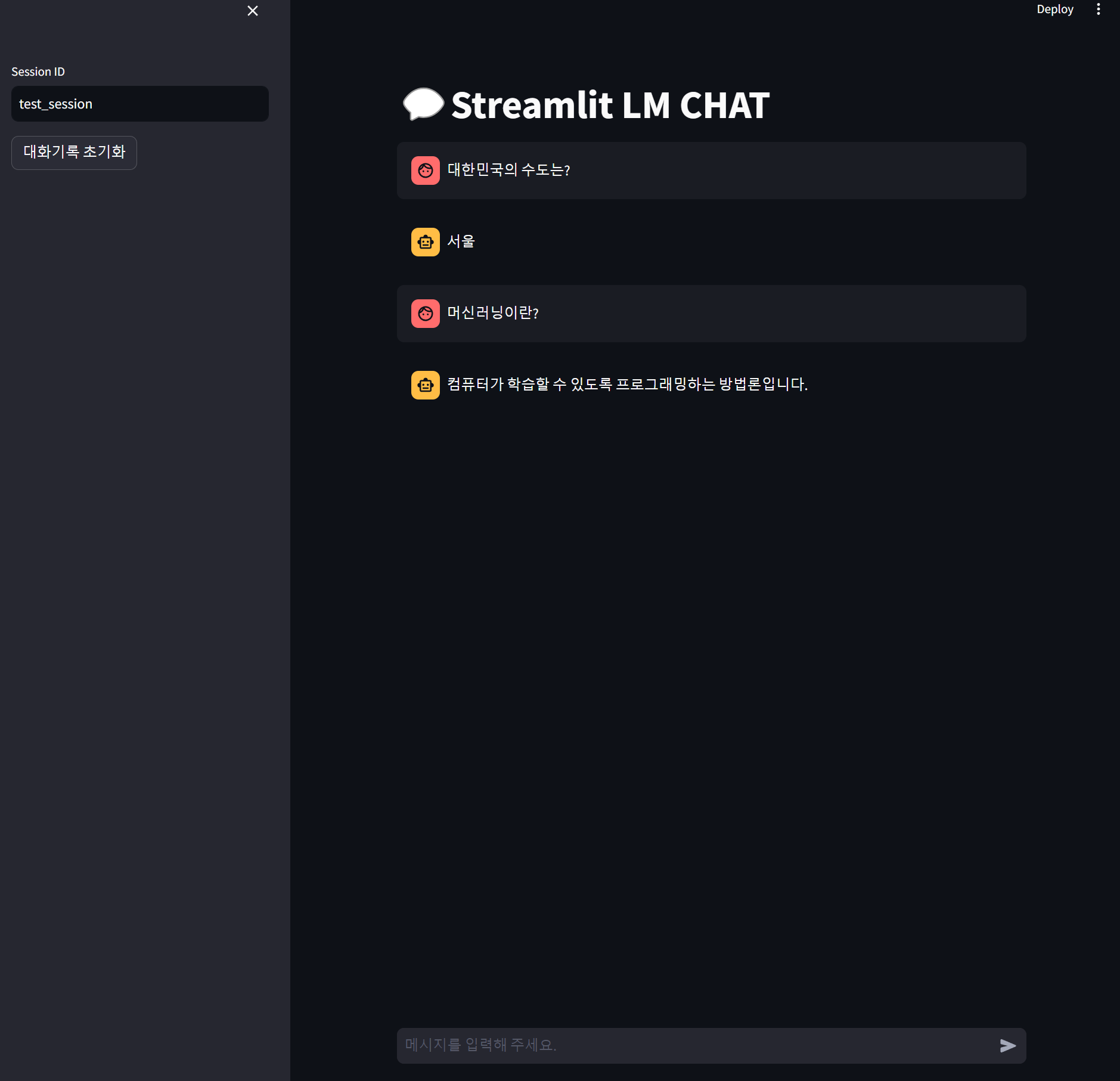
LM Studio 에서는 아래처럼 동작하는 모습을 확인할 수 있습니다.
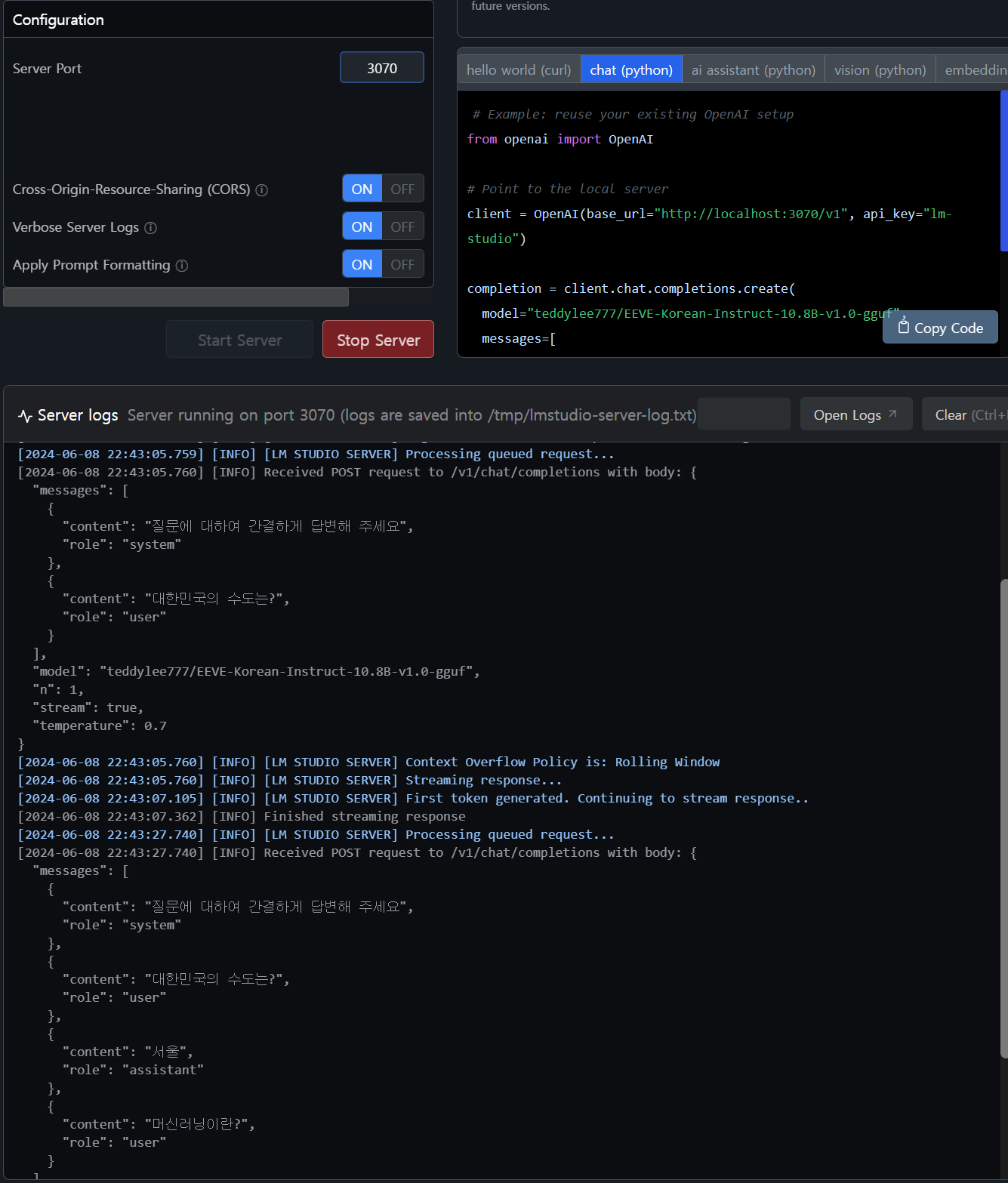
아래 처럼 질문과 응답이 처리되고 있는걸 확인 가능합니다.

컴퓨터 사양이 좋은 편이긴하지만 Open AI 의 응답 속도 보다 느립니다.
'코딩 > Python_AI' 카테고리의 다른 글
| FastAPI index.html 시작 페이지로 만들기 (0) | 2024.06.11 |
|---|---|
| .env 파일에서 OPENAI_API_KEY 처리하기 (0) | 2024.06.08 |
| streamlit 으로 나만의 GPT 채팅 서비스 제작하는 방법 (0) | 2024.06.08 |
| Open API 사용을 위한 Key 발급 받기 및 요금 (0) | 2024.06.08 |
| LM Studio 에서 LLM 로컬 서버 띄우기 (0) | 2024.06.06 |