BitNet - CPU에서 실행되는 LLM 테스트 하기
BitNet - CPU에서 실행되는 LLM 테스트 하기
로컬 LLM 처리시 GPU 가 없으면 정말 느립니다.
GPU가 없어도 CPU 로도 빠르게 응답을 할수 있도록 해주는 프레임워크를 MS 에서 내놨습니다.
그래서 한번 실행해서 실제 눈으로 확인을 해보려합니다.
https://github.com/microsoft/BitNet
GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs
Official inference framework for 1-bit LLMs. Contribute to microsoft/BitNet development by creating an account on GitHub.
github.com
위 사이트를 참고 했습니다.
우선 Visual Studio installer 를 실행해서 아래 C++ 항목을 체크하고 오른쪽에 Windows 용 C++ Clang 도구를 설치합니다.

이제 git 에서 소스를 끌어온 후 해당 폴더로 이동합니다.
(전 WSL 설정이 이상해 져서 그냥 Windows 환경에서 테스트했습니다.)
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
해당 폴더로 이동후 관련 Package 를 설치해 줍니다.
pip install -r requirements.txt저는 이미 설치된 것도 있고 버전이 안맞는 것도 있었는데 문제는 안되었습니다.

아래 명령을 실행해줍니다.
아래 명령으로 CMake 빌드와 model 다운로드까지 해줍니다.
python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s
이제 준비는 마무리 되었고 질문을 해봅니다. 우선 사이트내용대로 질문해 봤습니다.
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:" -n 6 -temp 0결과

-n 뒤의 숫자가 단어의 수 입니다. 좀 늘려서 다른걸 질문해 봤습니다.
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Explain the mysteries of the universe\nAnswer:" -n 100 -temp 0결과
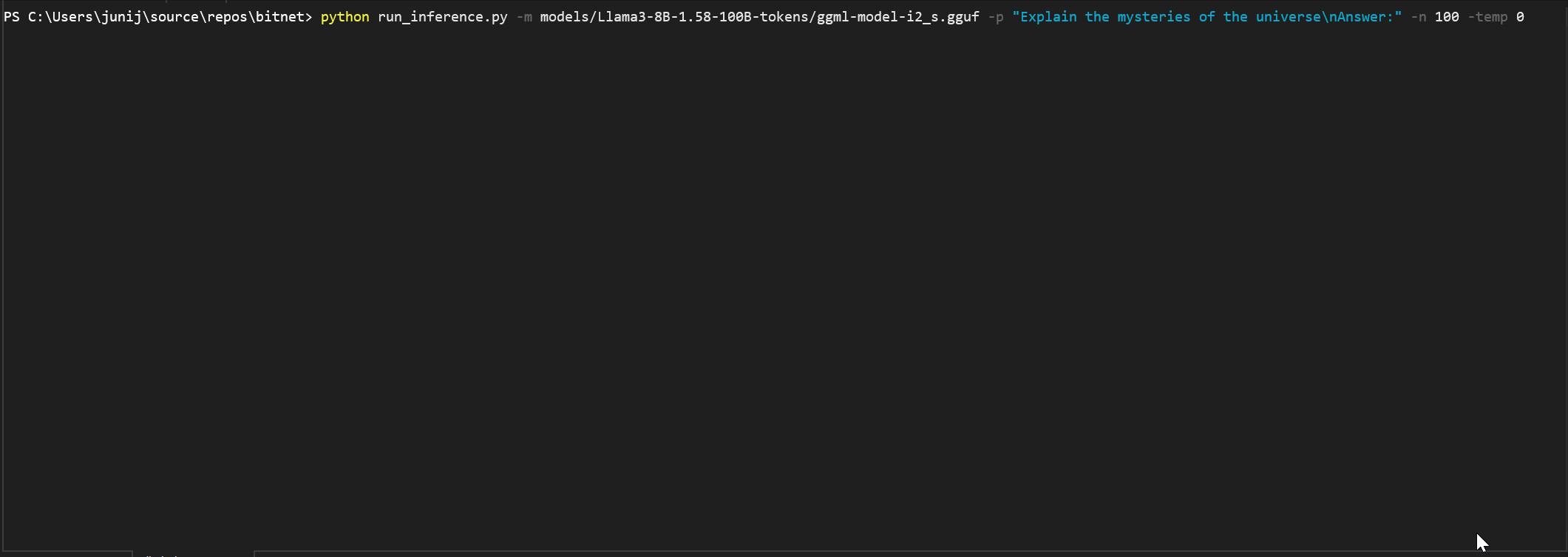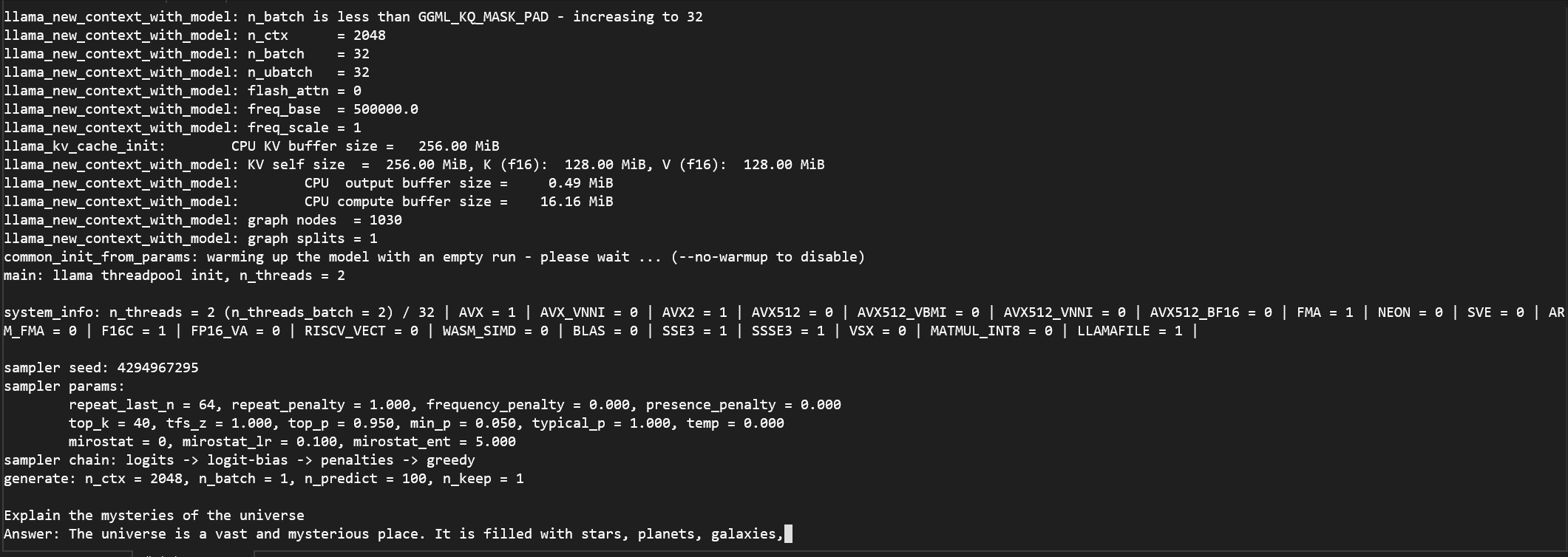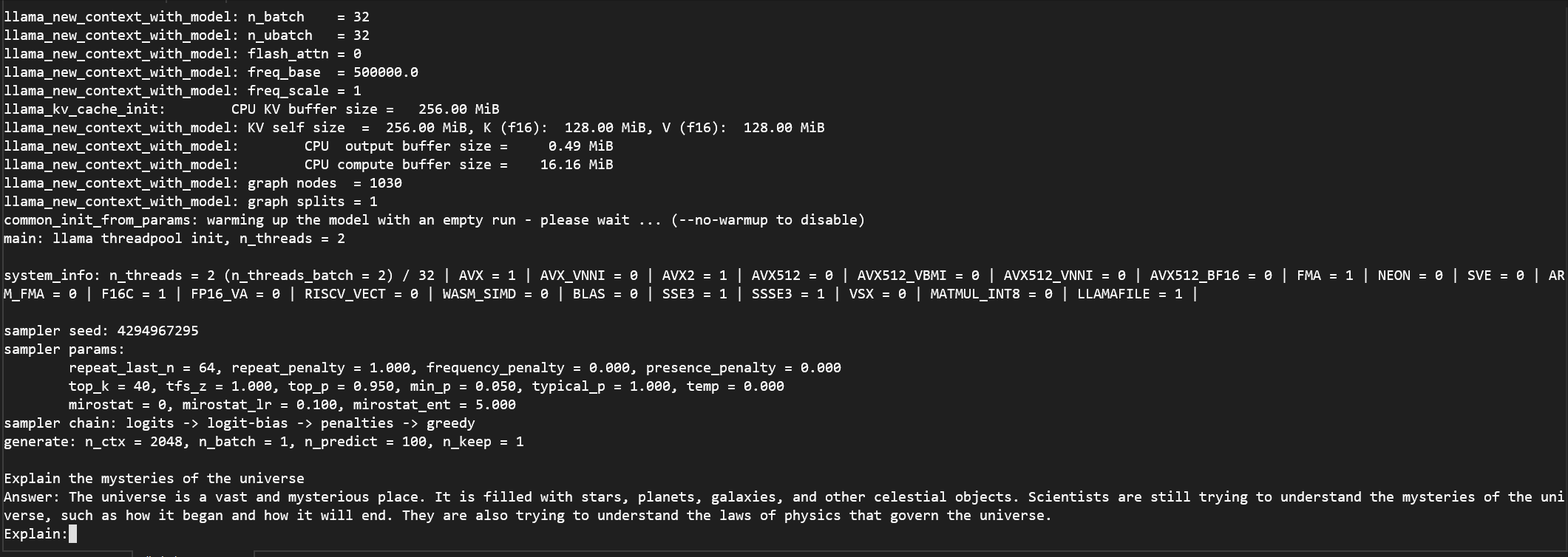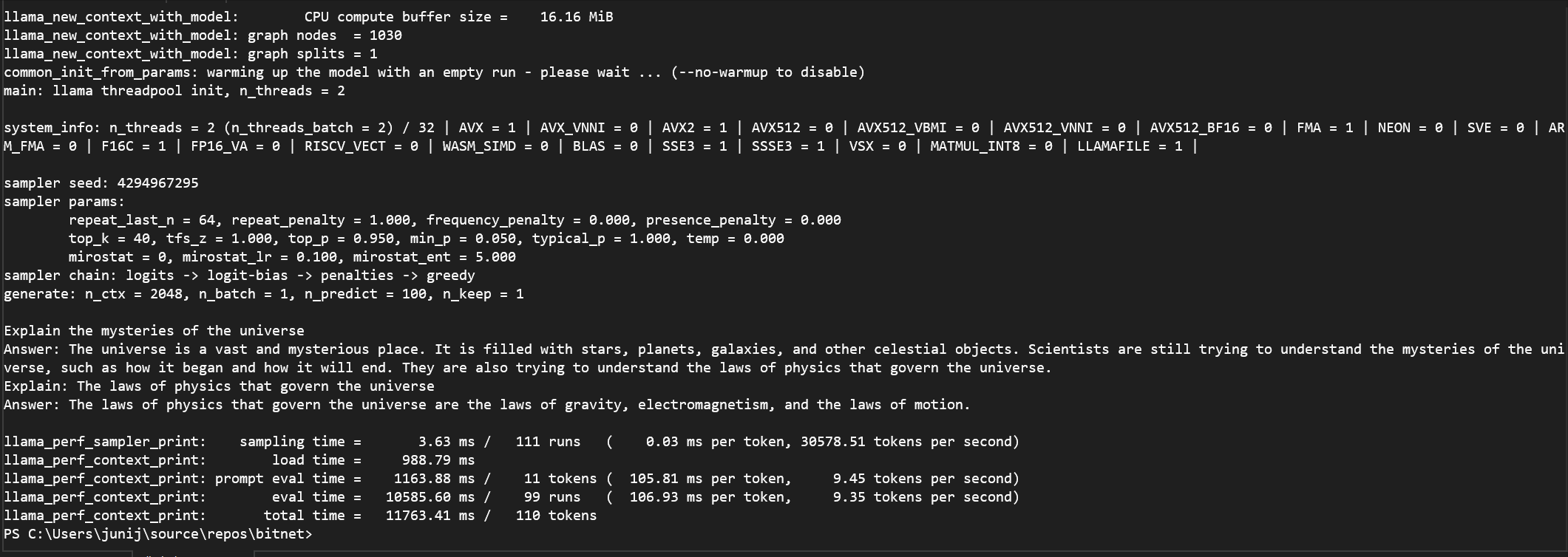
원래 CPU 로 하게되면 정말 느린데 BitNet 을 이용하니 답변이 빠릅니다.
이제 경량화 모델같은 경우는 CPU 로 돌려도 부족함이 없을것 같습니다.
'코딩 > Python_AI' 카테고리의 다른 글
| Python에서 2차원 배열 중 특정 열의 값을 모두 바꾸기 (0) | 2024.10.27 |
|---|---|
| FAISS 뷰어 (0) | 2024.10.22 |
| 로컬에 streamlit 로 llama 3.2 Vision 채팅창 만들기 (0) | 2024.10.15 |
| CUDA 버전 확인하기 (0) | 2024.10.15 |
| Torch not compiled with CUDA enabled 에러 해결하기 (0) | 2024.10.15 |