ChatOpenAI 와 FastAPI 챗 서버에 Tool Calling 기능 추가하기

ChatOpenAI 와 FastAPI 챗 서버에 Tool Calling 기능 추가하기
이전 포스팅에서 이어집니다.
2026.01.20 - [코딩/Python_AI] - ChatOpenAI 와 FastAPI 를 이용해 Streaming 채팅 구현하기
ChatOpenAI 와 FastAPI 를 이용해 Streaming 채팅 구현하기
ChatOpenAI 와 FastAPI 를 이용해 Streaming 채팅 구현하기 이번 글에서는 FastAPI + SSE 기반 스트리밍 챗 서버를 만들고, OpenAI SDK 대신 LangChain의 ChatOpenAI를 사용해 구현하는 방법을 알아봅니다.client / server
keistory.tistory.com
이전 글에서는 FastAPI + SSE(Server-Sent Events) 기반의 스트리밍 챗 서버를 구현하고, OpenAI SDK 대신 LangChain의 ChatOpenAI 를 사용해 실시간 응답을 처리하는 방법을 알아 봤습니다.
이번에는 Tool Calling 기능을 서버에서 처리하고 Tool 실행 결과를 다시 LLM 으로 전달하는 구조로 만들어봅니다.
Tool 정의
먼저 LangChain Tool을 하나 정의합니다. 입력된 문자열의 길이를 반환하는 간단한 Tool입니다.
@tool
def getStringLength(text: str) -> int:
"""입력된 문자열의 길이를 반환한다."""
print(f"\n>>> [도구 실행] getStringLength 호출됨! 입력값: {text}")
return len(text)LangChain의 @tool 데코레이터를 사용하면 LLM이 대화 흐름을 분석해 Tool 호출이 필요하다고 판단할 경우, 자동으로 해당 Tool을 호출하도록 요청하게 됩니다.
Tool 연결
ChatOpenAI 에 bind_tools 로 정의한 tool 을 연결합니다.
toolList = [getStringLength]
async def generateStream(chatRequest : ChatRequest):
try:
chatOpenAI = (ChatOpenAI(
model = chatRequest.model,
temperature = chatRequest.temperature,
max_tokens = chatRequest.max_tokens,
streaming = True
).bind_tools(toolList))
......이렇게 하면 스트리밍 응답 중 LLM이 Tool 호출이 필요하다고 판단할 경우 tool_calls 이벤트가 발생합니다.
Tool Handling
if fullAIMessageChunk and fullAIMessageChunk.tool_calls:
messageList.append(fullAIMessageChunk)
for toolCall in fullAIMessageChunk.tool_calls:
toolName = toolCall["name"]
toolArguments = toolCall["args"]
toolFunction = toolDictionary.get(toolName)
if not toolFunction:
result = f"Error : Unknown tool '{toolName}'"
else:
try:
result = await anyio.to_thread.run_sync(toolFunction.invoke, toolArguments)
except Exception as exception:
result = f"Error executing {toolName} : {str(exception)}"
toolMessage = ToolMessage(content = str(result),tool_call_id = toolCall["id"])
messageList.append(toolMessage)
yield f"data: {json.dumps({'type' : 'tool_result', 'tool' : toolName, 'result' : result}, ensure_ascii = False)}\n\n"
continue여기서 중요한 점은 Tool 실행 결과를 반드시 ToolMessage 형태로 다시 LangChain에게 전달해야 합니다.
이 과정을 거쳐야 LLM이 “Tool 실행 결과를 인지한 상태”로 다음 응답을 이어서 생성하게됩니다.
전체 소스
(이전 포스팅에서 작성한 스트리밍 구조 위에 Tool Calling 처리 로직만 추가된 형태)
server.py
# uv add python-dotenv langchain langchain-openai fastapi uvicorn
import json
import uvicorn
import anyio
from dotenv import load_dotenv
from pydantic import BaseModel
from typing import List
from typing import Optional
from pydantic import Field
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.messages import AIMessage
from langchain_core.messages import SystemMessage
from langchain_core.messages import ToolMessage
from langchain_openai import ChatOpenAI
from fastapi import FastAPI
from fastapi import HTTPException
from fastapi.responses import StreamingResponse
load_dotenv()
class Message(BaseModel):
role : str
content : str
class ChatRequest(BaseModel):
messages : List[Message]
model : str = "gpt-4o-mini"
temperature : Optional[float] = Field(default = 0.7, ge = 0, le = 2)
max_tokens : Optional[int ] = None
@tool
def getStringLength(text: str) -> int:
"""입력된 문자열의 길이를 반환한다."""
print(f"\n>>> [도구 실행] getStringLength 호출됨! 입력값: {text}")
return len(text)
toolList = [getStringLength]
toolDictionary = {tool.name : tool for tool in toolList}
def getLangchainMessageList(messageList : List[Message]):
targetMessageList = []
for message in messageList:
if message.role == "system":
targetMessageList.append(SystemMessage(content = message.content))
elif message.role == "user":
targetMessageList.append(HumanMessage(content = message.content))
elif message.role == "assistant":
targetMessageList.append(AIMessage(content = message.content))
else:
raise ValueError(f"Unknown role : {message.role}")
return targetMessageList
async def generateStream(chatRequest : ChatRequest):
try:
chatOpenAI = (ChatOpenAI(
model = chatRequest.model,
temperature = chatRequest.temperature,
max_tokens = chatRequest.max_tokens,
streaming = True
).bind_tools(toolList))
messageList = getLangchainMessageList(chatRequest.messages)
while True:
fullAIMessageChunk = None
async for aiMessageChunk in chatOpenAI.astream(messageList):
if fullAIMessageChunk is None:
fullAIMessageChunk = aiMessageChunk
else:
fullAIMessageChunk += aiMessageChunk
if aiMessageChunk.content:
yield f"data: {json.dumps({'type' : 'content', 'content' : aiMessageChunk.content}, ensure_ascii = False)}\n\n"
if aiMessageChunk.tool_calls:
for toolCall in aiMessageChunk.tool_calls:
yield f"data: {json.dumps({'type' : 'tool_call_start', 'tool' : toolCall['name']}, ensure_ascii = False)}\n\n"
if fullAIMessageChunk and fullAIMessageChunk.tool_calls:
messageList.append(fullAIMessageChunk)
for toolCall in fullAIMessageChunk.tool_calls:
toolName = toolCall["name"]
toolArguments = toolCall["args"]
toolFunction = toolDictionary.get(toolName)
if not toolFunction:
result = f"Error : Unknown tool '{toolName}'"
else:
try:
result = await anyio.to_thread.run_sync(toolFunction.invoke, toolArguments)
except Exception as exception:
result = f"Error executing {toolName} : {str(exception)}"
toolMessage = ToolMessage(content = str(result),tool_call_id = toolCall["id"])
messageList.append(toolMessage)
yield f"data: {json.dumps({'type' : 'tool_result', 'tool' : toolName, 'result' : result}, ensure_ascii = False)}\n\n"
continue
else:
break
yield "data: [DONE]\n\n"
except Exception as exception:
print(f"STREAMING ERROR : {str(exception)}")
yield f"data: {json.dumps({'type' : 'error', 'error' : str(exception)}, ensure_ascii = False)}\n\n"
fastAPI = FastAPI()
@fastAPI.post("/v1/chat/completion")
async def processChatCompletion(chatRequest : ChatRequest):
if not chatRequest.messages:
raise HTTPException(status_code = 400, detail = "Messages cannot be empty")
return StreamingResponse(generateStream(chatRequest), media_type = "text/event-stream", headers= {"Cache-Control" : "no-cache", "Connection" : "keep-alive"})
@fastAPI.get("/health")
async def processHealth():
return {"status" : "healthy"}
if __name__ == "__main__":
uvicorn.run(fastAPI, host = "0.0.0.0", port = 8000)
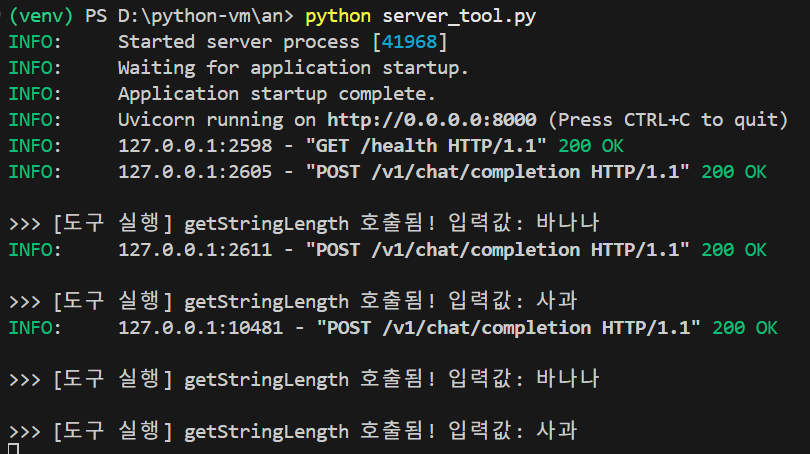
결과

'코딩 > Python_AI' 카테고리의 다른 글
| Qwen3-TTS 사용해 보기 (0) | 2026.01.29 |
|---|---|
| LangChain으로 도구 호출 승인 시스템 구현하기 (0) | 2026.01.25 |
| ChatOpenAI 와 FastAPI 를 이용해 Streaming 채팅 구현하기 (0) | 2026.01.20 |
| LiteLLM Proxy 대시보드 설정하기 (0) | 2025.08.24 |
| LiteLLM으로 여러 AI 모델을 한 번에 사용하기 (0) | 2025.08.11 |