OPENAI LogProb 란?

OPENAI LogProb 란?
주어진 텍스트에 대한 모델의 토큰 확률의 로그 값 을 의미합니다.
로그 확률은 특히 확률 값이 매우 작을 때 유용하게 사용됩니다.
이를 통해 계산의 수치적 안정성을 확보하고, 더 작은 값들을 다룰 수 있게 됩니다. 로그 확률은 확률 모델, 특히 자연어 처리(NLP)와 머신러닝에서 자주 사용됩니다.
토큰이란 문장을 구성하는 개별 단어나 문자 등의 요소를 의미하고, 확률은 모델이 그 토큰을 예측할 확률을 나타냅니다.
예시코드
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI
# 객체 생성
llm_with_logprob = ChatOpenAI(
temperature=0.1, # 창의성 (0.0 ~ 2.0)
max_tokens=1024, # 최대 토큰수
model_name="gpt-3.5-turbo", # 모델명
).bind(logprobs=True)
# 질의내용
question = "대한민국의 수도는 어디인가요?"
# 질의
response = llm_with_logprob.invoke(question)
# 결과
print(f"[결과]: {response}")결과
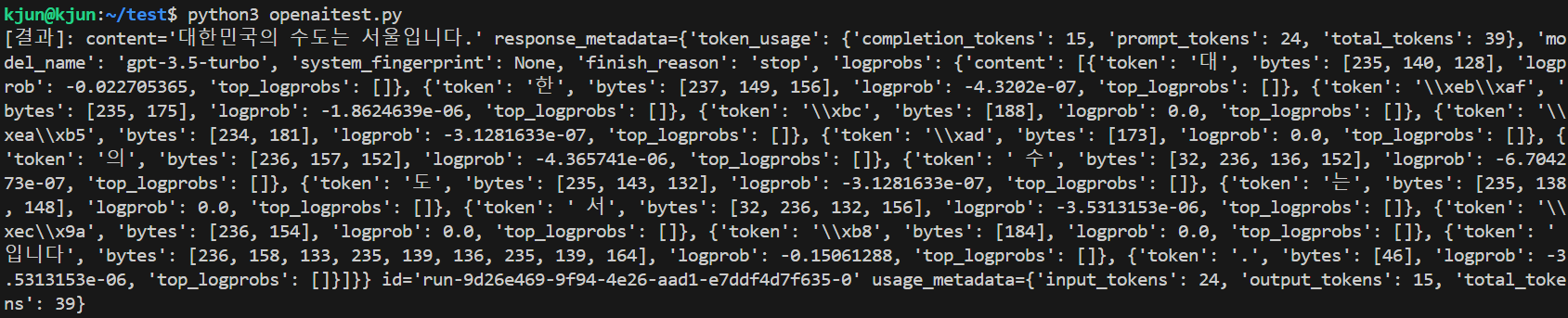
[결과]: content='대한민국의 수도는 서울입니다.' response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 24, 'total_tokens': 39}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': {'content': [{'token': '대', 'bytes': [235, 140, 128], 'logprob': -0.022705365, 'top_logprobs': []}, {'token': '한', 'bytes': [237, 149, 156], 'logprob': -4.3202e-07, 'top_logprobs': []}, {'token': '\\xeb\\xaf', 'bytes': [235, 175], 'logprob': -1.8624639e-06, 'top_logprobs': []}, {'token': '\\xbc', 'bytes': [188], 'logprob': 0.0, 'top_logprobs': []}, {'token': '\\xea\\xb5', 'bytes': [234, 181], 'logprob': -3.1281633e-07, 'top_logprobs': []}, {'token': '\\xad', 'bytes': [173], 'logprob': 0.0, 'top_logprobs': []}, {'token': '의', 'bytes': [236, 157, 152], 'logprob': -4.365741e-06, 'top_logprobs': []}, {'token': ' 수', 'bytes': [32, 236, 136, 152], 'logprob': -6.704273e-07, 'top_logprobs': []}, {'token': '도', 'bytes': [235, 143, 132], 'logprob': -3.1281633e-07, 'top_logprobs': []}, {'token': '는', 'bytes': [235, 138, 148], 'logprob': 0.0, 'top_logprobs': []}, {'token': ' 서', 'bytes': [32, 236, 132, 156], 'logprob': -3.5313153e-06, 'top_logprobs': []}, {'token': '\\xec\\x9a', 'bytes': [236, 154], 'logprob': 0.0, 'top_logprobs': []}, {'token': '\\xb8', 'bytes': [184], 'logprob': 0.0, 'top_logprobs': []}, {'token': '입니다', 'bytes': [236, 158, 133, 235, 139, 136, 235, 139, 164], 'logprob': -0.15061288, 'top_logprobs': []}, {'token': '.', 'bytes': [46], 'logprob': -3.5313153e-06, 'top_logprobs': []}]}} id='run-9d26e469-9f94-4e26-aad1-e7ddf4d7f635-0' usage_metadata={'input_tokens': 24, 'output_tokens': 15, 'total_tokens': 39}
내용을 보면 알수 있듯이 중간중간 logprobs 값이 추가로 출력됩니다.
'코딩 > Python_AI' 카테고리의 다른 글
| OPENAI 이미지 만들기 (0) | 2024.06.20 |
|---|---|
| OPENAI 스트리밍 출력하기 (0) | 2024.06.20 |
| OPENAI LLM 초간단 예제 (0) | 2024.06.19 |
| GPT4ALL 사용해 보기 (0) | 2024.06.16 |
| 나만의 ChatGPT 만들기 - text-generation-webui (0) | 2024.06.15 |